KIV Tour
Feature Overview
Specification Language
The functional approach uses higher-order algebraic specifications. The first-order part is a subset of CASL. Specifications are built up from elementary specifications with the operations enrichment, union, renaming, parameterization and actualization. Specifications have a loose semantics and may include generation principles to define inductive data types.
For the state-based approach KIV offers four approaches: Abstract State Machines (ASMs), parallel programs, and the direct verification of sequential Java programs (including generics).
ASMs define rules (abstract sequential programs that are executed atomically) to describe state transitions. The semantics of an ASM is the set of traces generated by the transition relation defined by the rules of the ASM. Our variant of ASMs is based on algebraically specified data types. The abstract programs used to define rules used include parallel assignments, (infinite) nondeterminism (with choose) and mutually recursive procedures.
Parallel programs extend the sequential ones with additional operators to execute programs in parallel, using shared variables: both (weak-fair and unfair) interleaving as well as asyncronous parallel execution are supported. An await-operator is used for synchronisation.
Proof Support: Higher-Order, Dynamic and Temporal Logic
In KIV, proofs for specification validation, design verification, and program verification are supported by an advanced interactive deduction component based on proof tactics. It combines a high degree of automation with an elaborate interactive proof engineering environment.
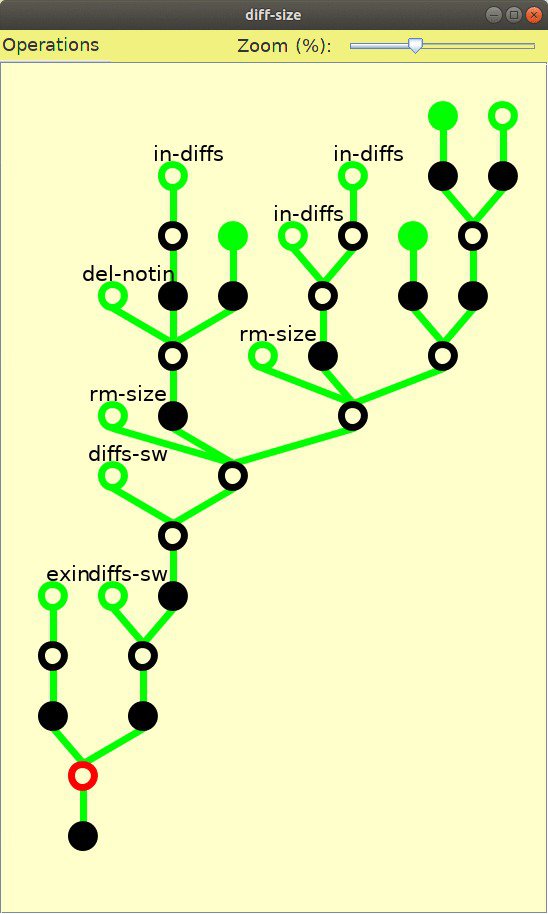
Deduction is based on a sequent calculus with explicit proof trees that can be graphically visualized (see left), saved and edited. Beginners, who want to learn sequent calculus can switch to using its very basic rules. For doing larger case studies, the basic rules are too low-level (they would lead to proof trees with thousands of steps). Therefore KIV uses proof tactics like simplification of higher-order logic formulas, lemma application, induction and the symbolic execution of programs. These collapse many basic steps into a single step.
To automate proofs, KIV offers a number of heuristics. Among others, heuristics for induction, unfolding of procedure calls and quantifier instantiation are provided. Heuristics can be chosen freely, and changed any time during the proof. Additionally, a `problem specific' heuristic exists which is easily adaptable to specific applications. Usually, the heuristics manage to find 80 - 100 % of the required proof steps automatically.
The conditional rewriter in KIV (called simplifier) handles thousands of rules very efficiently by compiling them to executable functional programs. Rules may be higher-order, conditions of rules may be checked either by recursive simplifier calls or by checking occurrence in the current goal. Some extensions of standard rewrite rules are rewriting modolo AC (associativity and/or commutativity), elimination rules and forward reasoning. As the structure of a formula helps to understand its meaning, the KIV simplifier always preserves this structure. The user explicitly chooses the rewrite and simplification rules. Different sets of simplification rules can be chosen for different tasks.
Verification of partial or total correctness individual programs is supported using a calculus based on Dynamic Logic. The proof strategy is based on symbolic execution of programs, invariants for loops and induction for recursive procedures. Due to the use of Dynamic Logic, the calculus for sequential programs is not limited to the verification of properties of a single program. It is also possible to prove properties involving several programs like program inclusion, which is useful for refinement.
For abstract programs the calculus supports total correctness of nondeterministic programs even with infinite nondeterminism (in terms of weakest precondition calculus it can handle all monotonic predicate transformers).
The calculus for verifying parallel programs is based on a powerful temporal logic, which extends CTL* and ITL. Like ITL, the logic has finite (termination!) and infinite traces, and embeds programs directly as formulas. No encoding into transition systems as e.g. in TLA is necessary. This allows to keep the intuitive principle of symbolic execution from sequential programs, thus allowing for a high degree of automation. Since the interleaving operator has a compositional semantics, modular reasoning over individual threads is supported. In particular, various forms of rely-guarantee rules (with or without deadlocking and termination) are derivable (see this paper and this paper for more details on the logic). An important application of parallel programs we a currently looking into is the verification of lock-free algorithms for multi-core processors, see the VeriCAS project for details.
Proof Engineering
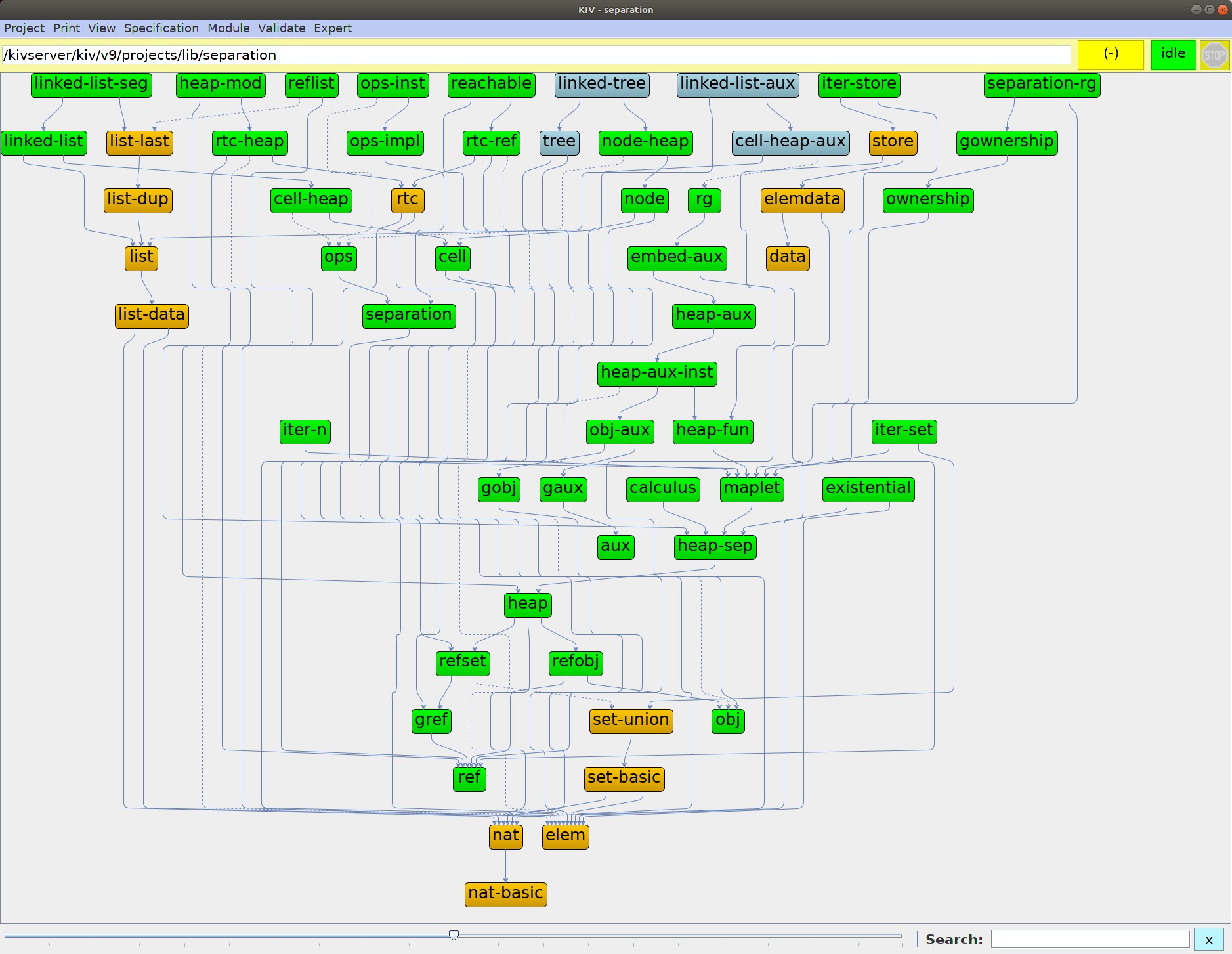
In KIV, formal specifications of software and system designs are represented explicitly as directed acyclic graphs called development graphs. Each node corresponds to a specification component or an ASM. Each node has a theorem base attached. Theorem bases initially contain axioms, ASM rules, and parallel programs and automatically generated proof obligations for refinements. The theorem base also stores theorems added by the user (proved and yet unproved ones), and manages proofs and their dependencies.
Frequently, the problem in engineering high assurance systems is not to verify proof obligations affirmatively, but rather to interpret failed proof attempts that may indicate errors in specifications, programs, lemmas etc. Therefore, KIV offers a number of proof engineering facilities to support the iterative process of (failed) proof attempts, error detection, error correction and re-proof. Dead ends in proof trees can be cut off, proof decisions may be withdrawn both chronologically and non-chronologically. Unprovable subgoals can be detected by automatically generating counter examples. This counter example can be traced backwards through the proof to the earliest point of failure. Thereby the user is assisted in the decision whether the goal to prove is not correct, proof decisions were incorrect, or there is a flaw in the specification. After a correction the goal must be re-proved. Here another interesting feature of KIV, the strategy for proof reuse, can be used. Both successful and failed proof attempts are reused automatically to guide the verification after corrections. This goes far beyond proof replay or proof scripts. We found that typically 90% of a failed proof attempt can be recycled for the verification after correction.
The correctness management in KIV ensures that changes to or deletions of specifications, modules, and theorems do not lead to inconsistencies, and that the user can do proofs in any order (not only bottom up). It guarantees that only the minimal number of proofs are invalidated after modifications, that there are no cycles in the proof hierarchy and that finally all used lemmas and proof obligations are proved (in some sub-specification).
Refinement
One of the strengths of KIV is verification of developments starting with an abstract designs down to executable code using refinement. KIV offers several variants of refinement, depending on the type of system specified. Traditionally, for functional specifications, KIV has supported algebraic refinement in the form of modules for a long time (see this paper).
Newer case studies use various forms of state-based refinement, most prominently ASM refinement (see this paper, this paper and the corresponding KIV project). ASM refinement comes with a modularization theorem that decomposes the correctness proofs for a refinement into proofs showing the commutativity of diagrams consisting of m abstract and n concrete steps. Such m:n diagrams generalize the usual 1:1 diagrams used in forward and backward simulations of data refinement. Case studies include the verification of a Prolog compiler and the Mondex case study on the security of an electronic purse implemented on Smartcards.
KIV also supports standard data refinement (the specifications are explained here as part of the solution to the original Mondex challenge) and IO automata refinement (given here for comparison with ASM refinement). A form of data refinement allows to refine abstract programs to Java code (see this paper) was also used in the Mondex case study.
A current project that uses ASM refinement is the Flashix project on the development of a fully verified Flash file system.
Graphical User Interface
KIV offers a powerful graphical user interface (see this paper) which has been constantly improved over the years. The intuitive user interface allows easy access to KIV for first time users, and is an important prerequisite for managing large applications. The interface is object oriented, and is implemented in Java to guarantee platform independency.
The top-level object of a development, the development graph, is displayed graphically (an example is above). The theorem base, which is attached to each development node, is arranged in tables, and context sensitive popup menus are provided for manipulation. While proving a theorem, the user is able to restrict the set of applicable tactics by selecting a context, i.e. a formula or term in the goal, with the mouse. This is extremely helpful for applying rewrite rules, as the set of hundreds of rewrite rules is reduced to a small number of applicable rules for the selected context. Proofs are presented as trees, where the user can click on nodes to inspect single proof steps.
In large applications, the plentitude of information may be confusing. Therefore, important information is summarized, and more details are displayed on request. Different colors are used to classify the given information. A special font allows the use of a large number of mathematical symbols.
KIV automatically produces LaTeX as well as XML documentation for a development on different levels of detail (see the KIV projects page for various examples of the latter). Specifications, implementations, theorem bases, proof protocols, and various kinds of statistics are pretty printed. The user is encouraged to add comments to specifications, which are also used to automatically produce a data dictionary. As several users may work simultaneously on a large project, the documentation facilities of KIV are very important. The automatically extracted information can also be included into reports.

Institute for Software & Systems Engineering
The Institute for Software & Systems Engineering (ISSE), directed by Prof. Dr. Wolfgang Reif, is a scientific institution within the Faculty of Applied Computer Science of the University of Augsburg. In research, the institute supports both fundamental and application-oriented research in all areas of software and systems engineering. In teaching, the institute facilitates the further development of the faculty's and university's relevant course offerings.