News
Best Paper Award at the CVsports Workshop at CVPR 2025
Our paper "Towards Ball Spin and Trajectory Analysis in Table Tennis Broadcast Videos via Physically Grounded Synthetic-to-Real Transfer" won the Best Paper Award at the 11th International Workshop on Computer Vision in Sports (CVsports) This workshop took place as part of this year's CVPR 2025 in Nashville, Tennessee.

Thesis Defense of Katja Ludwig
Two Papers Accepted at the CVSports@CVPR'25 Workshop
Efficient 2D to Full 3D Human Pose Uplifting including Joint Rotations" by Katja Ludwig, Yuliia Oksymets, et al.

Paper accepted on CVSports at CVPR 2025

Best Paper Award at CV4WS@WACV
For the paper „SkipClick: Combining Quick Responses and Low-Level Features for Interactive Segmentation in Winter Sports Contexts” the authors Robin Schön, Julian Lorenz, Daniel Kienzle and Rainer Lienhart received the best paper award at the workshop on Computer Vision for Winter Sports. The workshop took place at the WACV 2025 in Tucson, Arizona.

Paper accepted at the CV4ws@WACV 2025 workshop
A paper with the title „SkipClick: Combining Quick Responses and Low-Level Features for Interactive Segmentation in Winter Sports Contexts” by Robin Schön, Julian Lorenz, Daniel Kienzle and Rainer Lienhart has been accepted to the Workshop for “Computer Vision for Winter Sports (CV4WS)”. This workshop will take place in context of the WACV 2025 in Tucson, AZ.
Paper accepted (Oral) at the European Conference on Computer Vision (ECCV) 2024
The paper "A Fair Ranking and New Model for Panoptic Scene Graph Generation" by Julian Lorenz, Alexander Pest, Daniel Kienzle, Katja Ludwig, and Rainer Lienhart has been accepted for ECCV 2024 as an Oral Paper.
The authors discuss significant flaws in commonly used evaluation protocols for Panoptic Scene Graph Generation. They present a solution to this problem and evaluate existing publications based on the new findings.
Finally, a new state-of-the-art architecture for Panoptic Scene Graph Generation is presented.
More information can be found here: https://lorjul.github.io/fair-psgg/

Paper accepted at the eLVM@CVPR 2024 workshop
A paper with the title “Adapting the Segment Anything Model During Usage in Novel Situations” by Robin Schön, Julian Lorenz, Katja Ludwig and Rainer Lienhart has been accepted at the workshop for “Efficient Large Vision Models (eLVM)“. The workshop will be held jointly with the CVPR 2024 in Seattle. The paper presents a method for adapting the Segment Anything Model (SAM) during test time without the aid of additional training data. Instead, the method uses information with is generated during usage in order to generate pseudo labels.
Paper for SG2RL@CVPR 2024 accepted
The paper "A Review and Efficient Implementation of Scene Graph Generation Metrics" by Julian Lorenz, Robin Schön, Katja Ludwig, and Rainer Lienhart is accepted at the Workshop on Scene Graphs and Graph Representation Learning at CVPR 2024.
The authors review existing scene graph generation metrics and provide precise definitions that were lacking in this field. Additionally, they introduce an efficient and easy to use python package that implements all discussed metrics. To improve comparability of new scene graph generation methods, the authors provide a benchmarking service that enables an easy evaluation of scene graph generation models.
More information can be found here: https://lorjul.github.io/sgbench/
Open Positions for PhD students

Paper accepted at International Conference on 3D Vision (3DV) 2024
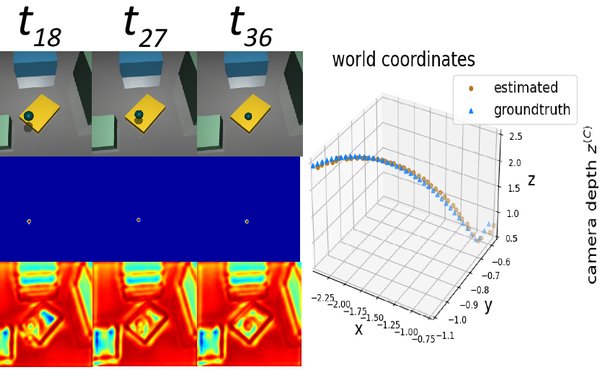
The paper titled "Towards Learning Monocular 3D Object Localization Using the Physical Laws of Motion" by Daniel Kienzle, Julian Lorenz, Katja Ludwig and Rainer Lienhart was accepted to the International Conference on 3D Vision (3DV) 2024. The paper describes a new method for localizing objects in 3D without the need for 3D ground truth. Instead, the method uses knowledge of physical laws to learn the task.
See https://kiedani.github.io/3DV2024/ for additional information on the paper.